Trước khi bắt đầu tìm hiểu các khái niệm cơ bản trong xác suất, chúng ta cần xem lại các khái niệm cơ bản trong thống kê – một lĩnh vực quan hệ chặt chẽ với xác suất – tại https://ngocminhtran.com/2019/06/10/machine-learning-mot-vai-khai-niem-co-ban-trong-thong-ke-statistic/
Sự kiện phụ thuộc (dependence) và sự kiện độc lập (independence)
Hai sự kiện (hay biến cố) E và F được gọi là phụ thuộc (dependence) nếu biết thông tin về sự kiện E (hay F) xảy ra thì chúng ta có thể suy ra thông tin khi sự kiện F (hay E) xảy ra. Ngược lại, nếu biết thông tin về E (hay F) mà ta không biết thông tin gì về F (hay E) thì hai sự kiện E và F gọi là độc lập (independence).
Ví dụ tung đồng xu hai lần, nếu gọi E là sự kiện tung đồng xu thứ nhất là mặt ngửa, F là sự kiện tung đồng xu thứ hai có mặt ngửa, thì E và F là hai sự kiện độc lập vì E hay F không ảnh hưởng đến kết quả xảy ra của nhau. Nếu gọi G là sự kiện cả hai lần tung đồng xu là mặt sấp thì E và G là hai sự kiện phụ thuộc vì từ E ta có thể suy ra sự kiện G ( trong trường hợp này chúng ta có thể suy ra là G sai).
Gọi P(E) là xác suất xảy ra sự kiện E, P(F) là xác suất xảy ra sự kiện F và P(E,F) là xác suất xảy ra cả hai sự kiện E và F. Nếu E và F độc lập thì P(E,F) là tích của P(E) và P(F):
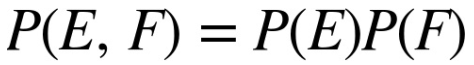
Xác suất có điều kiện ( Conditional Probability)
Xác suất có điều kiện là xác suất một biến cố E xảy ra, biết rằng biến cố F xảy ra, ký hiệu: P(E|F).
P(E|F) có thể được tính như sau:
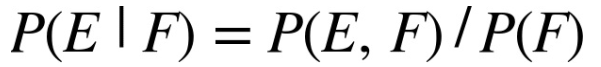
Suy ra:
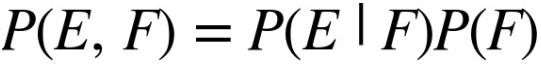
Nếu E và F độc lập, ta có:
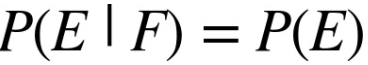
Xét ví dụ một gia đình có hai người con biết rằng:
- Giới tính mỗi người con có thể là nam hay nữ
- Giới tính người con thứ hai độc lập giới tính người con thứ nhất
Như vậy, chúng ta có 4 trường hợp giới tính của các người con như sau:
| Giới tính người con thứ nhất | Giới tính người con thứ hai |
| Nam | Nam |
| Nữ | Nữ |
| Nam | Nữ |
| Nữ | Nam |
Gọi A là sự kiện giới tính cả hai người con không là Nữ
B là sự kiện giới tính một Nam và một Nữ (không quan tâm người con thứ nhất hay thứ hai)
C là sự kiện giới tính cả hai người con là Nữ
D là sự kiện giới tính người con thứ hai là Nữ
E là sự kiện ít nhất một người con là Nữ
P(A) = 3/4
P(B) = 2/4 = 1/2
P(C) = 1/4
P(D) = 2/4 = 1/2
P(E) = 3/4
P(C|D) = P(C,D)/P(D) = P(C)/P(D) = (1/4) / (1/2) = 1/2; P(C,D) = P(D) vì hai sự kiện C, D chỉ là một sự kiện C.
P(C|E) = P(C,E)/P(E) = P(C)/P(E) = (1/4) / (3/4) = 1/3
Dưới đây là đoạn mã Python minh họa tính xác suất các sự kiện A, B, C, D, E:
import random
def chon_gioi_tinh():
return random.choice(["Nam", "Nu"])
A = 0
B = 0
C = 0
D = 0
E = 0
random.seed(0)
# chọn ngẫu nhiên trong 10000 lần
for _ in range(10000):
thu_nhat = chon_gioi_tinh()
thu_hai = chon_gioi_tinh()
if not(thu_nhat == "Nu" and thu_hai == "Nu"):
A += 1
if (thu_nhat == "Nam" and thu_hai == "Nu")
or (thu_nhat == "Nu" and thu_hai == "Nam"):
B += 1
if thu_nhat == "Nu" and thu_hai == "Nu":
C += 1
if thu_hai == "Nu":
D += 1
if thu_nhat == "Nu" or thu_hai == "Nu":
E += 1
print("P(A) = ", A/10000) # ~ 3/4
print("P(B) = ", B/10000) # ~ 1/2
print("P(C) = ", C/10000) # ~ 1/4
print("P(D) = ", D/10000) # ~ 1/2
print("P(E) = ", E/10000) # ~ 3/4
print("P(C|D) = ", C/D) # ~ 1/2
print("P(C|E) = ", C/E) # ~ 1/3
Định lý Bayes
Giả sử chúng ta cần tính xác suất điều kiện của sự kiện E khi biết sự kiện F xảy ra, tức là P(E|F), nhưng chúng ta chỉ biết thông tin về xác suất điều kiện của sự kiện F khi sự kiện E xảy ra, tức là biết P(F|E). Lúc này, định lý Bayes được sử dụng.
Công thức Bayes:
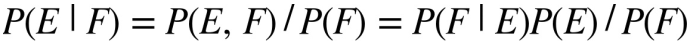
Nếu kí hiệu ¬E là sự kiện ‘không E’ thì công thức Bayes cũng có thể được viết trong dạng khác như sau:
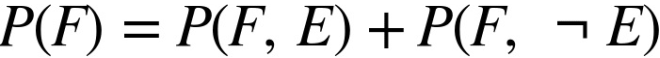
Tương đương
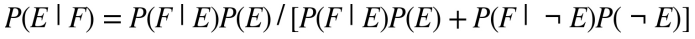
Biến ngẫu nhiên (random variable)
Trong một phép thử ngẫu nhiên (Randomness tests), đầu ra (outcome) của nó có thể là giá trị số hoặc không phải. Ví dụ phép thử ngẫu nhiên là tung một đồng xu lên và xét mặt nào của đồng xu ở phía trên, thì kết quả đầu ra có thể là {sấp, ngửa} (đầu ra không phải là số). Ví dụ phép thử ngẫu nhiên là tung con súc sắc và xem mặt nằm phía trên là có mấy chấm, thì kết quả đầu ra có thể là {1,2,3,4,5,6} (đầu ra là số). Tuy nhiên, trong các ứng dụng của thống kê, người ta muốn mỗi đầu ra đều gắn với một đại lượng đo đạc được, hay còn gọi là thuộc tính có giá trị là số. Để thực hiện điều này, người ta định ra biến ngẫu nhiên để ánh xạ mỗi đầu ra của một phép thử ngẫu nhiên với một giá trị số.
Một số người cho rằng gọi tên biến ngẫu nhiên là một sự nhầm lẫn, do một biến ngẫu nhiên không phải là một biến mà là một hàm số ánh xạ các biến cố tới các số.
Định nghĩa toán học của biến ngẫu nhiên: Cho không gian xác suất (Ω, A, P). Một hàm X: Ω → R là một biến ngẫu nhiên giá trị thực nếu với mọi tập con Ar = { ω: X(ω) ≤ r } trong đó r ∈ R, ta cũng có Ar ∈ A. Định nghĩa này có tầm quan trọng ở chỗ nó cho phép ta xây dựng hàm phân bố của biến ngẫu nhiên.
Biến ngẫu nhiên có 2 dạng:
- Rời rạc (discrete): tập giá trị nó là rời rạc, tức là đếm được. Ví dụ như mặt chấm của con xúc xắc
- Liên tục (continuous): tập giá trị là liên tục tức là lấp đầy 1 khoảng trục số. Ví dụ giá nhà đất
Phân phối xác suất (probability distribution)
Trong Toán học và Thống kê, một phân phối xác suất hay thường gọi hơn là một hàm phân phối xác suất là quy luật cho biết cách gán mỗi xác suất cho mỗi khoảng giá trị của tập số thực, sao cho các tiên đề xác suất được thỏa mãn.
Có hai dạng phân phối xác suất là phân phối rời rạc (discrete distribution) và phân phối liên tục (continuous distribution). Sự kiện tung đồng xu tương ứng với phân phối rời rạc vì xác suất của sự kiện này gắn liền với các giá trị rời rạc, ví dụ mặt sấp hay ngửa. Tuy nhiên, trong thực tế chúng ta thường chỉ sử dụng phân phối liên tục trong khoảng (a, b) với a và b là các số thực.
Vì có vô hạn số giữa a và b nên chúng ta thường thể hiện một phân phối liên tục qua hàm mật độ xác suất (probability density function – pdf).
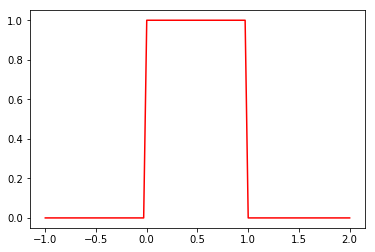
Dạng đơn giản nhất của phân phối liên tục là phân phối đều liên tục (uniform distribution) trong khoảng giá trị là 0 và 1 với hàm mật độ xác suất có thể được định nghĩa bằng Python như sau:
import numpy as np import matplotlib.pyplot as plt x = np.linspace(-1, 2, 100) def uniform_pdf(x): return 1 if x >= 0 and x < 1 else 0 y = [] for i in range(100): y.append(uniform_cdf(x[i])) plt.plot(x, y, 'r') plt.show()
Biểu đồ thể hiện cho phân phối liên tục đều qua hàm pdf trông như sau:
Một dạng hàm phổ biến khác thường dùng cho phân phối liên tục là hàm phân phối tích lũy (cumulative distribution function – cdf). Hàm phân phối tích lũy cho phân phối liên tục đều có thể định nghĩa trong Python như sau:
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(-1, 2, 100)
def uniform_cdf(x):
if x < 0:
return 0
elif x < 1:
return x
else:
return 1
y = []
for i in range(100):
y.append(uniform_cdf(x[i]))
plt.plot(x, y, 'r')
plt.show()
Biểu đồ thể hiện cho phân phối liên tục đều qua hàm cdf trông như sau:
Phân phối chuẩn (normal distribution)
Là một dạng của phân phối liên tục và là vua của các phân phối. Phân phối chuẩn còn gọi là phân phối Gauss hay phân phối đường cong chuông vì biểu đồ của nó có dạng hình chuông. Phân phối chuẩn phụ thuộc vào hai tham số là giá trị trung bình (mean), kí hiệu là µ (mu), và độ lệch chuẩn (standard deviation), kí hiệu σ (sigma). Giá trị mean là đỉnh của hình chuông, độ lệch chuẩn là độ rộng của chuông.
Hàm mật độ xác suất cho phân phối chuẩn có công thức như sau:
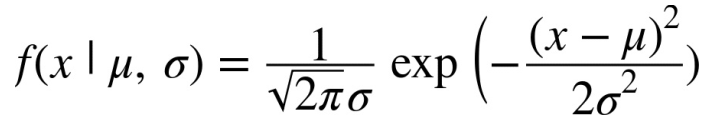
Định nghĩa với Python:
def normal_pdf(x, mu=0, sigma=1): sqrt_two_pi = math.sqrt(2 * math.pi) return (math.exp(-(x-mu) ** 2 / 2 / sigma ** 2) / (sqrt_two_pi * sigma))
Với các giá trị khác nhau của µ và σ, chúng ta có biểu đồ các phân phối chuẩn như sau:
xs = [x / 10.0 for x in range(-50, 50)]
plt.plot(xs,[normal_pdf(x,sigma=1) for x in xs],'-',label='mu=0,sigma=1')
plt.plot(xs,[normal_pdf(x,sigma=2) for x in xs],'--',label='mu=0,sigma=2')
plt.plot(xs,[normal_pdf(x,sigma=0.5) for x in xs],':',label='mu=0,sigma=0.5')
plt.plot(xs,[normal_pdf(x,mu=-1) for x in xs],'-.',label='mu=-1,sigma=1')
plt.legend()
plt.title("Các trường hợp của pdf")
plt.show()
Kết quả:
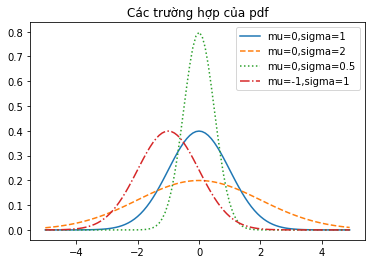
Nếu µ = 0 và σ = 1, chúng ta gọi là phân phối chuẩn tắc (normal standard distribution).
Hàm phân phối tích lũy của phân phối chuẩn có thể được định nghĩa trong Python dùng hàm toán học math.erf:
def normal_cdf(x, mu=0,sigma=1): return (1 + math.erf((x - mu) / math.sqrt(2) / sigma)) / 2
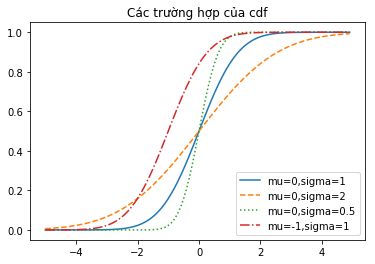
Với các giá trị khác nhau của µ và σ, chúng ta có biểu đồ các phân phối chuẩn với hàm phân phối tích lũy như sau:
xs = [x / 10.0 for x in range(-50, 50)]
plt.plot(xs,[normal_cdf(x,sigma=1) for x in xs],'-',label='mu=0,sigma=1')
plt.plot(xs,[normal_cdf(x,sigma=2) for x in xs],'--',label='mu=0,sigma=2')
plt.plot(xs,[normal_cdf(x,sigma=0.5) for x in xs],':',label='mu=0,sigma=0.5')
plt.plot(xs,[normal_cdf(x,mu=-1) for x in xs],'-.',label='mu=-1,sigma=1')
plt.legend(loc=4)
plt.title("Các trường hợp của cdf")
plt.show()
Kết quả:
Định lý giới hạn trung tâm (Central Limit Theorem)
Một trong những hữu ích của phân phối chuẩn là định lý giới hạn trung tâm. Định lý này nói rằng, một biến ngẫu nhiên được định nghĩa như trung bình của một số lớn của các biến ngẫu nhiên độc lập và phân phối đồng nhất là xấp xỉ phân phối chuẩn.
Cụ thể, nếu x1, x2,…,xn là các biến ngẫu nhiên với µ, σ và số n đủ lớn thì
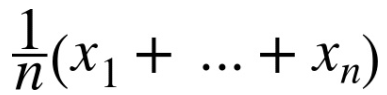
là giá trị xấp xỉ phân phối chuẩn với mean µ và độ lệch chuẩn là 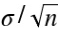
Với µ = 0 và σ = 1, ta có:
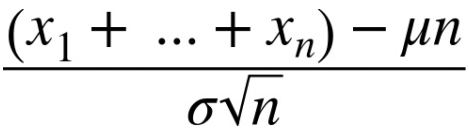
là giá trị xấp xỉ phân phối chuẩn.
Tầm quan trọng thực tiễn của định lý giới hạn trung tâm là phân phối chuẩn có thể được sử dụng như một xấp xỉ cho một số dạng phân phối khác. Minh họa cho điều này là các biến ngẫu nhiên nhị thức (binomial) với hai tham số là số lớn n và xác suất p.
Một biến ngẫu nhiên nhị thức Binomial(n,p) là tổng của n biến ngẫu nhiên Bernoulli(p) độc lập. Mỗi biến ngẫu nhiên Bernoulli(p) sẽ nhận giá trị 1 nếu xác suất là p và nhận giá trị 0 nếu xác suất là 1-p.
Biến ngẫu nhiên nhị thức Binomial(n,p) và biến ngẫu nhiên Bernoulli(p) có thể được cài đặt bằng Python như sau:
def bernoulli_trial(p): return 1 if random.random() < p else 0 def binomial(n, p): return sum(bernoulli_trial(p) for _ in range(n))
Giá trị µ của biến Bernoulli(p) là p và σ là 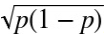 vì vậy, áp dụng định lý giới hạn trung tâm khi n đủ lớn, một biến Binomial(n,p) là xấp xỉ của một biến ngẫu nhiên chuẩn với µ là np và σ là
vì vậy, áp dụng định lý giới hạn trung tâm khi n đủ lớn, một biến Binomial(n,p) là xấp xỉ của một biến ngẫu nhiên chuẩn với µ là np và σ là 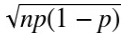 .
.
Chúng ta có thể thấy kết quả trên một cách trực quan bằng đoạn mã Python hoàn chỉnh sau:
import random
import matplotlib.pyplot as plt
import math
from collections import Counter
def normal_cdf(x, mu=0,sigma=1):
return (1 + math.erf((x - mu) / math.sqrt(2) / sigma)) / 2
def bernoulli_trial(p):
return 1 if random.random() < p else 0
def binomial(n, p):
return sum(bernoulli_trial(p) for _ in range(n))
def make_hist(p, n, num_points):
data = [binomial(n, p) for _ in range(num_points)]
# các biểu đồ cột là các nhị thức
histogram = Counter(data)
plt.bar([x - 0.4 for x in histogram.keys()],
[v / num_points for v in histogram.values()],0.8,color='0.75')
mu = p * n
sigma = math.sqrt(n * p * (1 - p))
# đường cong là xấp xỉ chuẩn
xs = range(min(data), max(data) + 1)
ys = [normal_cdf(i + 0.5, mu, sigma) - normal_cdf(i - 0.5, mu, sigma)for i in xs]
plt.plot(xs,ys)
plt.title("Phân phối nhị thức và Xấp xỉ chuẩn theo định lý giới hạn trung tâm")
plt.show()
make_hist(0.75, 100, 10000)
Kết quả:
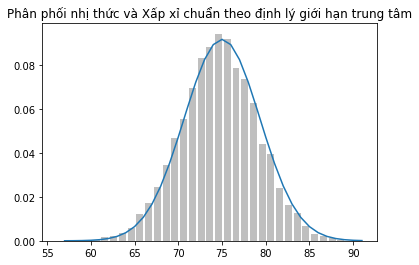
Lời kết
Trong bài viết này chúng ta chỉ khám phá một cách khái quát về xác suất – một trong những nền tảng quan trọng cho Machine Learning. Kiến thức xác suất và thống kê rất thú vị nhưng cũng không hề đơn giản và sau đây là các nguồn quan trọng để chúng ta có thể tiếp cận xác suất và thống kê:
Tiếng Anh
- Data Science from Scratch First Principles with Python
- https://www.dartmouth.edu/~chance/teaching_aids/books_articles/probability_book/amsbook.mac.pdf
- https://www.openintro.org/download.php?file=os3_tablet
Tiếng Việt:
Xem bài viết với Jupiter Notebook
