Hàm mất mát L1 và L2
Một trong các cách tiếp cận dùng để giải quyết bài toán Linear Regression là sử dụng hàm chi phí (cost function) hay cũng có thể gọi là hàm mất mát (loss function). Để minh họa chúng ta sẽ trở lại mô hình linear regresison đơn giản trong bài Phân tích ma trận Cholesky.
Giả sử chúng ta có một tập giá trị đầu vào x = {x1, x2,..,xn} và tập giá trị mong đợi y = {y1, y2, …, yn}. Chúng ta cũng có một mô hình tuyến tính hay hàm số f(xi) ánh xạ từ R -> R:
f(xi) = w1*xi + w0
Vấn đề chúng ta là tìm ra hằng số hay trọng số W = (w0, w1) tương ứng với xi sao cho f(xi) gần với yi nhất có thể, với i = 1,..,n. Để thực hiện được điều này, chúng ta cần định nghĩa một hàm chi phí hay hàm mất mát thể hiện sự chênh lệch giữa f(xi) và yi và đi tìm giá trị nhỏ nhất cho hàm này.
Có hai giải pháp định nghĩa hàm mất mát trong linear regression là sử dụng chuẩn L1 và chuẩn L2.
Hàm mất mát chuẩn L1 (Least absolute deviations – tạm dịch: Độ lệch tuyệt đối tối thiểu)
Hàm mất mát chuẩn L1 có dạng:
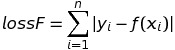
Hàm mất mát chuẩn L2 (Least square errors – tạm dịch: Lỗi bình phương tối thiểu) hay còn gọi là chuẩn Euclid (Euclidean norm)
Hàm mất mát chuẩn L2 có dạng:
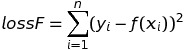
Để thuận tiện trong việc tính toán (tính đạo hàm), trong các tài liệu thường thêm hằng số ½ đến lossF:
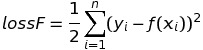
Sau khi định nghĩa hàm mất mát, vấn đề của chúng ta là tìm véc tơ trọng số W* sao cho
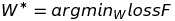
Tìm W* với lossF chuẩn L2 có thể tham khảo http://cs229.stanford.edu/notes/cs229-notes1.pdf
Sử dụng thư viện TensorFlow
Trong bài viết này chúng ta sẽ giải quyết bài toán linear regression đơn giản bằng cách định nghĩa hàm mất mát chuẩn L2 và sử dụng các phương thức từ thư viện TensorFlow để tìm W*. Thuật toán tham khảo từ http://cs229.stanford.edu/notes/cs229-notes1.pdf
Khởi tạo dữ liệu
Chúng ta cần khởi tạo dữ liệu để huấn luyện thuật toán:
x_train = np.linspace(0, 10, 100) y_train = x_train + np.random.normal(0,1,100)
Khai báo các biến, placeholder và các hằng số
Khởi tạo các hằng số tốc độ học (learning rate), số lần lặp qua tập dữ liệu để cập nhật các trọng số (training epoches), các placeholder và các biến trọng số:
# khởi tạo tốc độ học và số lần lặp learning_rate = 0.01 training_epoches = 100 # Khai báo các placeholder để feed dữ liệu từ x_train và y_train X = tf.placeholder(tf.float32) Y = tf.placeholder(tf.float32) # khai báo các biến trọng số w0 = tf.Variable(0.0, name="W0") w1 = tf.Variable(0.0, name="W1")
Định nghĩa hàm mất mát hay chi phí theo chuẩn L2
Trước hết chúng ta cần định nghĩa f(xi):
# f(xi) = xi*w1 + w0
def f(X, w1, w0):
return tf.add(tf.multiply(X, w1), w0)
f_xi = f(X, w1, w0)
Sau đó là định nghĩa hàm mất mát:
lossF = tf.square(Y-f_xi)
Định nghĩa hàm tìm giá trị tối ưu W*
Sử dụng thư viện TensorFlow để tìm giá trị nhỏ nhất cho lossF theo phương pháp Gradient Descent (tham khảo https://machinelearningcoban.com/2017/01/12/gradientdescent/ )
train_op = tf.train.GradientDescentOptimizer(learning_rate).minimize(lossF)
Thực hiện huấn luyện để tìm trọng số tối ưu W*
# khởi tạo session và các biến
sess = tf.Session()
init = tf.global_variables_initializer()
sess.run(init)
# Lặp qua tập dữ liệu để tìm W*
for epoch in range(training_epochs):
for (x, y) in zip(x_train, y_train):
sess.run(train_op, feed_dict={X: x, Y: y})
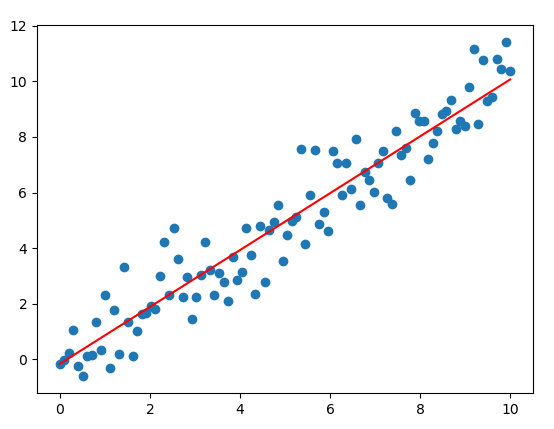
Hiển thị tập dữ liệu và đường thẳng tối ưu từ W*
# rút trích các giá trị trọng số tối ưu vừa tìm được w_val_0 = sess.run(w0) w_val_1 = sess.run(w1) sess.close() # Hiển thị tập dữ liệu plt.scatter(x_train, y_train) # Hiển thị đường thẳng của tập nghiệm tối ưu y_learned = x_train*w_val_1 + w_val_0 plt.plot(x_train, y_learned, 'r') plt.show()
Kết quả:
Mã nguồn hoàn chỉnh https://gist.github.com/TranNgocMinh/ad32c026f5bd725b7ec842ec9f52949c
