Các thuật toán trong Machine Learning (ML) chia thành 3 nhánh là supervised learning (tạm dịch: học giám sát), unsupervised learning (tạm dịch: hoc không giám sát) và reinforcement learning (tạm dịch: học tăng cường). Linear regression (tạm dịch: Hồi quy tuyến tính) là thuật toán thuộc nhánh supervised learning.
Bài viết này không đào sâu vào các khái niệm về ML, các nhánh learning hay linear regression vì có rất nhiều nguồn chất lượng chúng ta có thể tham khảo dễ dàng. Sau đây là một số nguồn:
Tiếng Anh:
- CS229 Lecture notes, Andrew Ng (http://cs229.stanford.edu/notes/cs229-notes-all/cs229-notes1.pdf)
- https://en.wikipedia.org/wiki/Machine_learning
Tiếng Việt:
- https://vi.wikipedia.org/wiki/H%E1%BB%8Dc_m%C3%A1y
- https://ongxuanhong.wordpress.com/2015/06/10/machine-learning-la-gi/
- https://machinelearningcoban.com/2016/12/28/linearregression/
Mô hình linear regression đơn giản
Giả sử chúng ta có một tập giá trị đầu vào x = {x1, x2,..,xn} và tập giá trị mong đợi y = {y1, y2, …, yn}. Chúng ta cũng có một mô hình tuyến tính hay hàm số f(xi) ánh xạ từ R -> R:
f(xi) = w1*xi + w0 (1)
Vấn đề chúng ta là tìm ra hằng số hay trọng số W = (w0, w1) tương ứng với xi sao cho f(xi) = yi, với i = 1,..,n. Trong thực tế, chúng ta chỉ có thể tìm được f(xi) gần yI nhất có thể nhưng để đơn giản chúng ta giả định là bằng.
Giả sử rằng x0 = 1, (1) có thể được viết lại như sau:
yi = f(xi) = w1*xi + w0*x0 (2)
Nếu biểu diễn dưới dạng vec tơ, (2) tương đương
X*WT = y (3)
Với
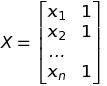
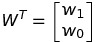
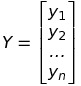
Chúng ta sẽ giải hệ (3) để tìm WT. Có nhiều cách giải, một cách giải là sử dụng Phân tích ma trận Cholesky.
Phân tích ma trận Cholesky
Theo phân tích Cholesky, một ma trận vuông X có thể được biểu diễn dưới dạng tích của ma trận tam giác dưới L và chuyển vị của nó tức LT:
X = L*LT
Ma trận vuông là lý tưởng vì trong thực tế sẽ là một ma trận kích thước bất kỳ nên thay vì sử dụng phân tích Cholesky cho X chúng ta sẽ thực hiện với X*XT vì tích của một ma trận với chuyển vị của nó luôn là một ma trận vuông, công thức lúc này:
X*XT = L*LT
Nhân hai vế phương trình (3) cho XT, ta có:
XT*X*WT = y*XT
Tương đương:
L*LT*WT = y*XT
Tương đương:
L*Z = y*XT (4) và LT*WT = Z (5)
Như vậy, để giải hệ phương trình (3) theo phân tích Cholesky chúng ta sẽ thực hiện 3 bước:
- Bước 1: Tìm Phân tích Cholesky L của X.XT
- Bước 2: Giải hệ phương trình L.Z = y.XT tìm Z
- Bước 3: Giải hệ phương trình LT.WT = Z tìm WT
Chúng ta sẽ dùng thư viện TensorFlow để giải hệ (3) theo 3 bước trên.
Dùng thư viện TensorFlow để tìm phân tích Cholesky và giải hệ phương trình tuyến tính
Bây giờ chúng ta sẽ giải quyết bài toán linear regression theo phương pháp phân tích Cholesky dùng thư viện TensorFlow theo các bước sau:
Bước 0: Khởi tạo dữ liệu
Chúng ta cần khởi tạo các dữ liệu dùng để huấn luyện gồm x_train và y_train
x_train = np.linspace(0, 10, 100) y_train = x_train + np.random.normal(0,1,100)
Kế tiếp chúng ta sẽ tạo ma trận X với kích thước 100X2, với cột đầu tiên là các giá trị x_train, cột thứ hai là cột số 1 là giá trị x0 mà chúng ta đã quy ước ở trên
x_vals_column = np.transpose(np.matrix(x_train)) ones_column = np.transpose(np.matrix(np.repeat(1, 100))) X = np.column_stack((x_vals_column, ones_column))
Nếu xuất X ra màn hình, kết quả:
[[ 0. 1. ]
[ 0.1010101 1. ]
[ 0.2020202 1. ]
[ 0.3030303 1. ]
…
Cuối cùng là khởi tạo ma trận y và các tensor:
# Create y matrix y = np.transpose(np.matrix(y_train)) # Create tensors X_tensor = tf.constant(X) y_tensor = tf.constant(y)
Bước 1: Tìm phân tích Cholesky L của X.XT
Sau khi đã khởi tạo ma trận X chúng ta sẽ tìm ma trận L của X.XT dùng phân tích Cholesky. Điều này có thể thực hiện dễ dàng bằng cách dùng hàm tf.cholesky() từ thư viện TensorFlow như sau:
# Find Cholesky Decomposition of X*XT tX_X = tf.matmul(tf.transpose(X_tensor), X_tensor) L = tf.cholesky(tX_X)
Bước 2: Giải hệ phương trình L.Z = y.XT tìm Z
Chúng ta sẽ tìm Z dùng hàm tf.matrix_solve từ thư viện TensorFlow như sau:
# Solve L*Z = y*XT for Z tX_y = tf.matmul(tf.transpose(X_tensor), y) Z = tf.matrix_solve(L, tX_y)
Bước 3: Giải hệ phương trình LT.WT = Z tìm WT
Trong bước cuối cùng này chúng ta sẽ dùng tf.matrix_solve để tìm WT, là tập các trọng số chúng ta cần tìm
# Solve LT*WT = Z for WT WT= tf.matrix_solve(tf.transpose(L), Z)
Bước 4: Tìm đường thẳng là tập nghiệm tối ưu
Bây giờ chúng ta sẽ trích xuất các trọng số và biểu diễn đường thẳng mô tả tập nghiệm tối ưu mà thuật toán tìm được:
solution_eval = sess.run(WT)
# Extract coefficients
w1= solution_eval[0][0]
w0 = solution_eval[1][0]
# Get best fit line
best_fit = []
for i in x_train:
best_fit.append(w1*i+w0)
# Plot the results
plt.plot(x_train, y_train, 'o', label='Data')
plt.plot(x_train,best_fit, 'r-', label='Best fit line', linewidth=3)
plt.legend(loc='upper left')
plt.show()
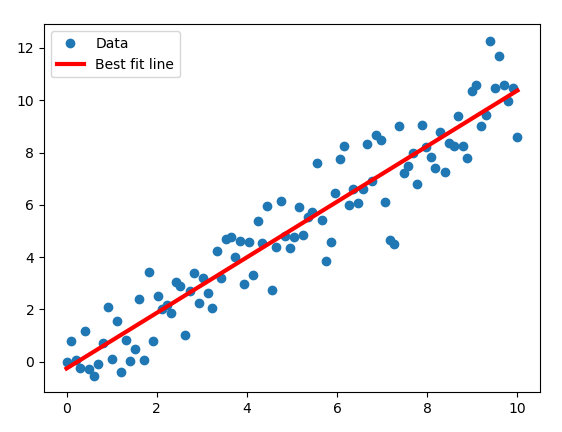
Có thể xem mã nguồn hoàn chỉnh tại GitHub.
Lời kết
Có nhiều cách tiếp cận để giải bài toán linear regression và một trong những cách đó là sử dụng phân tích ma trận Cholesky. Phân tích Cholesky cho một ma trận X không dễ dàng nhưng thật may mắn vì thư viện TensorFlow đã giúp chúng ta tiết kiệm rất nhiều thời gian. Trong các bài tiếp theo, chúng ta sẽ khám phá hơn nữa về sức mạnh của công cụ TensorFlow để giải quyết các vấn để của ML.
